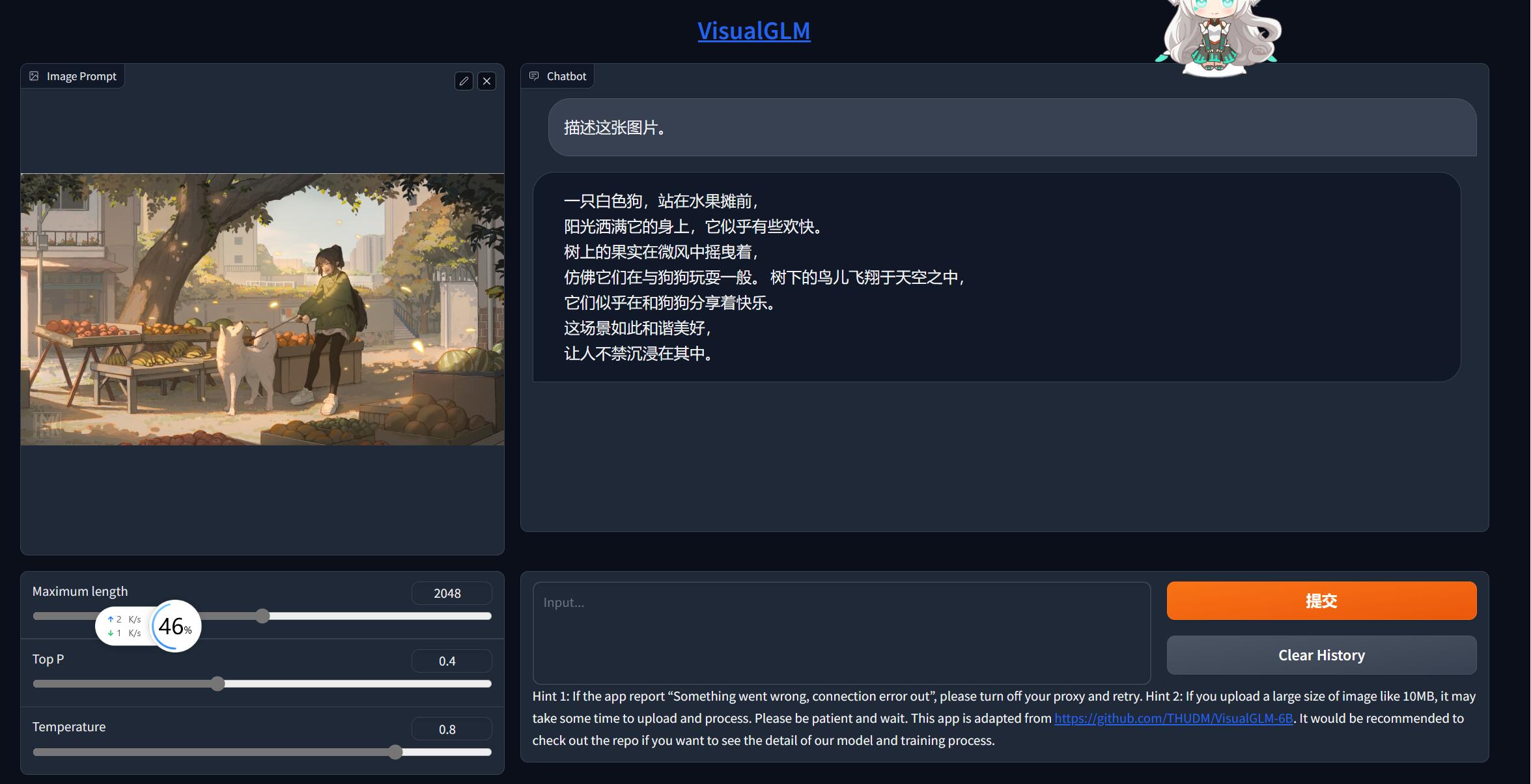
VisualGLM-6B-趋动云部署
VisualGLM-6B-趋动云部署
项目地址

开一台GPU
我选择的是AUTODL(因为便宜),注册登录后创建容器实例。
设备的要求:
- ≥50G的内存
- ≥24G的显存
镜像选择下面这一套就够用(至少现在是,以后如果不适配了可以另行调整)
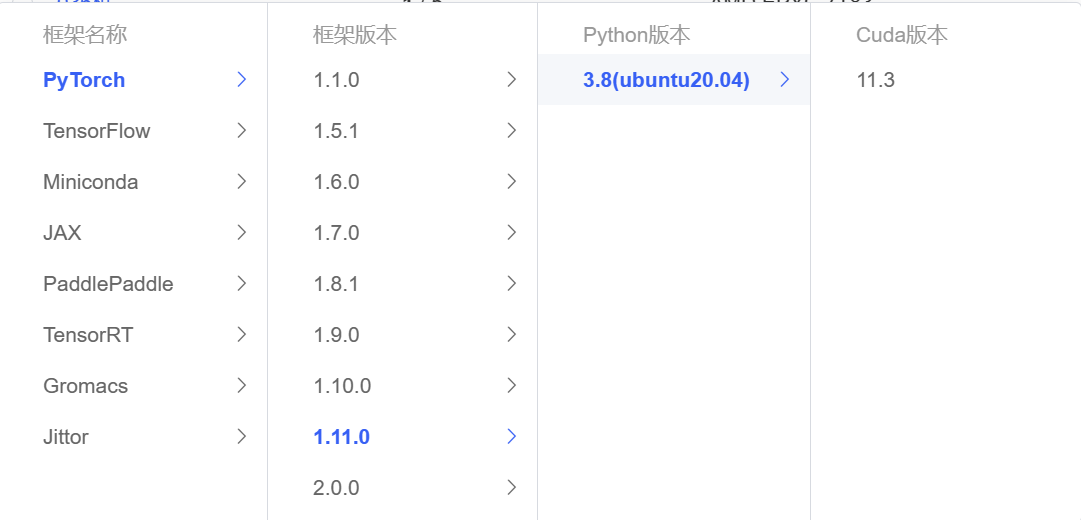
当然你看官方文档选配置就行
到这里准备工作结束
拉取源码
更新一下Ubuntu源
1 | apt update |
在数据盘中存放模型(防止放系统盘占用太多空间)
1 | cd autodl-tmp |
autodl-tmp是数据盘
然后就可以拉取源码了,放哪里你自己决定
1 | git clone https://github.com/THUDM/VisualGLM-6B.git |
这里拉取不成功的话可以多试几次
下载模型文件
根据官方文档
需要安装git-lfs
1 | sudo apt-get update |
这里如果出现下面这种报错,可以先git init
然后再git lfs install
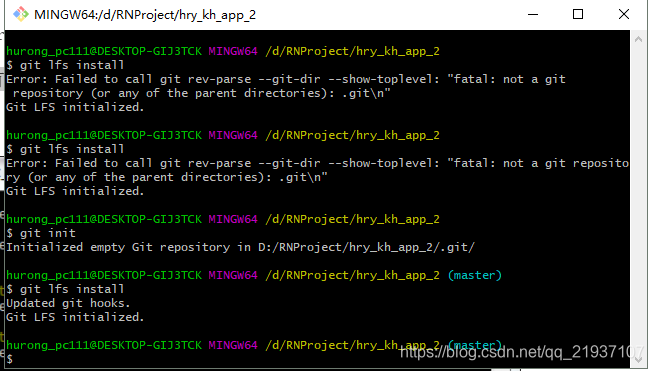
出现Git LFS initialized就可以了图中也有
继续在新建的文件夹下创建存放模型文件的文件夹,笔者为model
1 | mkdir model |
拉取模型文件
1 | git clone https://huggingface.co/THUDM/visualglm-6b |
这里需要等很久,因为模型文件大
安装依赖
进入项目文件夹
1 | cd VisualGLM-6B |
根据官方文档可以
1 | pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements_wo_ds.txt |
执行这个但是我记得我运行之后少个包,到时候你可以看着报错在下载
修改模型文件地址
找到你要运行的文件,这里以web_demo_hf.py为例子
找到main函数修改地址,默认是THUDM/visualglm-6b,修改成自己的,我们的应该是’/root/autodl-tmp/model/visualglm-6b’
把THUDM/visualglm-6b都替换掉
然后把最后一行demo.queue().launch(share=args.share, inbrowser=True, server_name='0.0.0.0', server_port=8080)
这个替换成demo.queue().launch(share=True, inbrowser=True, server_name='0.0.0.0', server_port=8080)
这样就可以得到一个可以访问的网址了
运行
切换到VisualGLM-6B文件夹
运行
1 | python web_demo_hf.py |
等待一段时间,加载模型完成后。复制生成的链接进行访问即可。
有一个像这样的url
1 | https://2164b527cc15e257b.gradio.live/ |
开玩