1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
| import requests
def get_encoded(account, password, scode, sxh, codeDogSequence=' '):
code = f"{account}%%%{password}%%%{codeDogSequence}"
encoded = ""
i = 0
while i < len(code):
if i < 55:
encoded += code[i]
n = int(sxh[i])
encoded += scode[:n]
scode = scode[n:]
else:
encoded += code[i:]
break
i += 1
return encoded
def get_scode_and_sxh(base_url, session=None):
"""
获取 scode 和 sxh
:param base_url: 例如 http://jwgl2024.ouc.edu.cn
:param session: requests.Session() 对象(可选,建议带上以保持 cookie)
:return: (scode, sxh)
"""
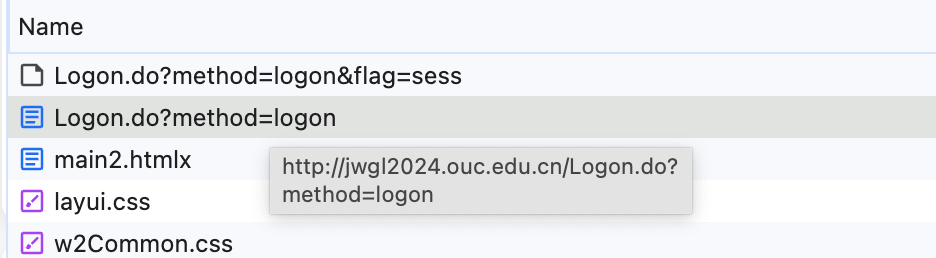
url = f"{base_url}/Logon.do?method=logon&flag=sess"
sess = session or requests.Session()
headers = {
"Accept": "text/plain, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Content-Length": "0",
"Origin": base_url,
"Pragma": "no-cache",
"Referer": f"{base_url}/",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36",
"X-Requested-With": "XMLHttpRequest"
}
resp = sess.post(url, headers=headers)
if resp.status_code == 200:
data = resp.text
if "#" in data:
scode, sxh = data.split("#", 1)
return scode, sxh
else:
raise Exception("返回内容格式不正确")
else:
raise Exception(f"请求失败,状态码: {resp.status_code}")
def login_jwgl(base_url, account, encoded, session=None):
"""
登录教务系统
:param base_url: 例如 http://jwgl2024.ouc.edu.cn
:param account: 用户账号
:param encoded: 加密后的encoded参数
:param session: requests.Session() 对象(可选)
:return: 登录后的响应内容
"""
url = f"{base_url}/Logon.do?method=logon"
sess = session or requests.Session()
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Content-Type": "application/x-www-form-urlencoded",
"Origin": base_url,
"Pragma": "no-cache",
"Referer": f"{base_url}/",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36"
}
data = {
"loginMethod": "logon",
"userlanguage": "0",
"userAccount": account,
"userPassword": "",
"encoded": encoded
}
resp = sess.post(url, headers=headers, data=data)
print("Cookies after login:", resp.cookies.get_dict())
return resp
if __name__ == "__main__":
account = ""
password = ""
base_url = "http://jwgl2024.ouc.edu.cn"
session = requests.Session()
home_url = base_url + "/"
home_resp = session.get(home_url)
scode, sxh = get_scode_and_sxh(base_url, session=session)
codeDogSequence = ' '
encoded = get_encoded(account, password, scode, sxh, codeDogSequence)
print("Encoded Input:", encoded)
resp = login_jwgl(base_url, account, encoded, session=session)
print("Login response status:", resp.status_code)
print("当前会话所有cookie:", session.cookies.get_dict())
with open("login_result.html", "w", encoding="utf-8") as f:
f.write(resp.text)
print("已保存到 login_result.html")
|